@spyl94 ~ Aurélien David



GraphQL ?
GraphQL est une syntaxe qui décrit comment demander des données.
Uniquement la couche transport de l'API.
Langage de requête de base de données.
Problème concret avec REST
Ajouter la liste d'utilisateurs ayant aimé des articles de blog.
Notre approche est de modifier l'endpoint /posts et de lui ajouter pour chaque article la liste d'utilisateurs ayant aimés.

Problème: l'application mobile est beaucoup plus lente à charger… sans avoir besoin des likes !
Solution 1: On ajoute un nouveau endpoint GET /posts/{id}/likes
😡 Une requête en plus pour chacun des articles.
Solution 2: On ajoute un nouveau endpoint GET /posts_with_likes
😡 Un endpoint desktop, un endpoint mobile, pas scalable...
Solution 3: On utilise une option du type ?fields=title,likes
😒 Complexifie l'implémentation, augmente le taux de MISS cache.
Une approche différente de concevoir une API
Au lieu d'avoir plusieurs endpoints «stupides», disposer d'un seul endpoint «intelligent» qui peut prendre des requêtes complexes, puis formatter la sortie de données sous quelque forme que ce soit.

GraphQL est utilisé depuis plus de quatre ans chez Facebook en production et a beaucoup évolué avant d'être ouvert à tous.
REST
GraphQL
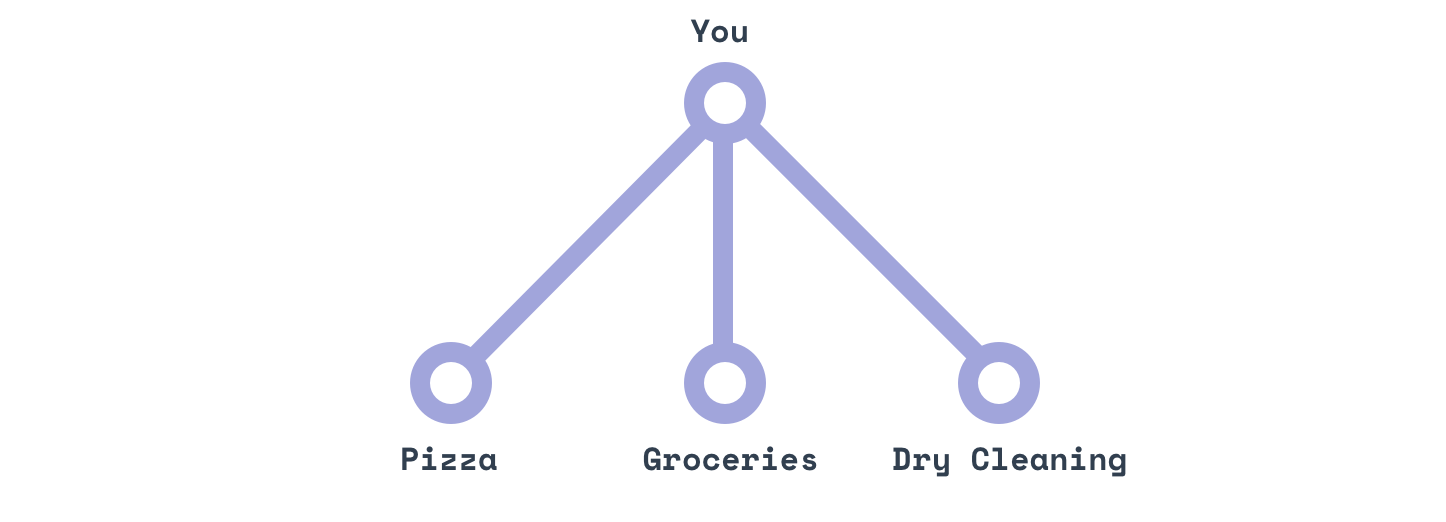
Trois appels à trois destinataires différents.
- “Mon linge propre“
- “Une margherita“
- “Une douzaine d'oeufs“
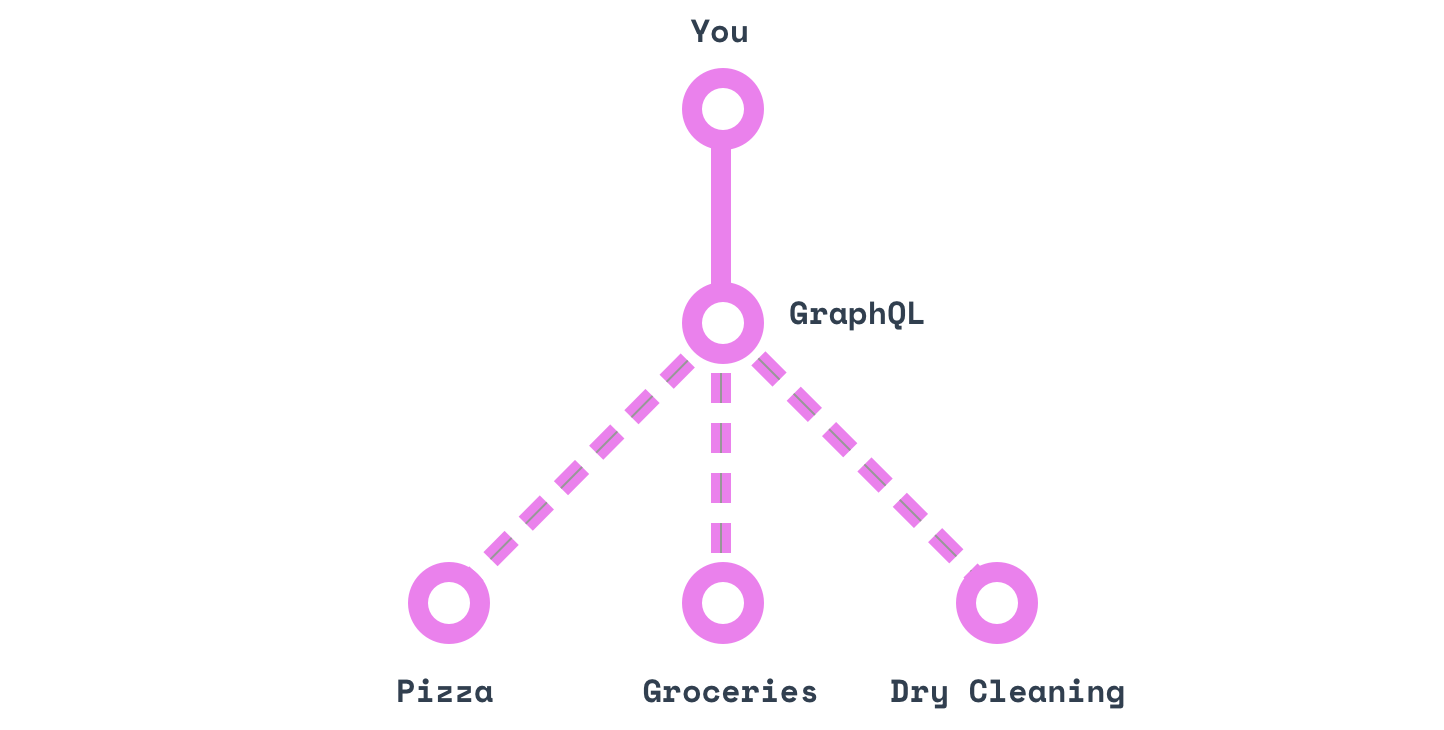
Un seul appel pour demander ce qu'on veut.
“Donne moi mon linge propre, une margherita et une douzaine d'oeufs.”
En d'autres termes, GraphQL établit un language pour parler à un assistant personnel magique.

Permet au client de préciser les données dont il a besoin.
Facilite l'agrégation des données de plusieurs sources.
Utilise un système de type pour décrire les données.
La requête que l'on fait à notre assistant personnel GraphQL est appelée une query, ça ressemble à ça :
query {
posts {
title
likes {
name
avatar
}
}
}
POST
/graphql➡️
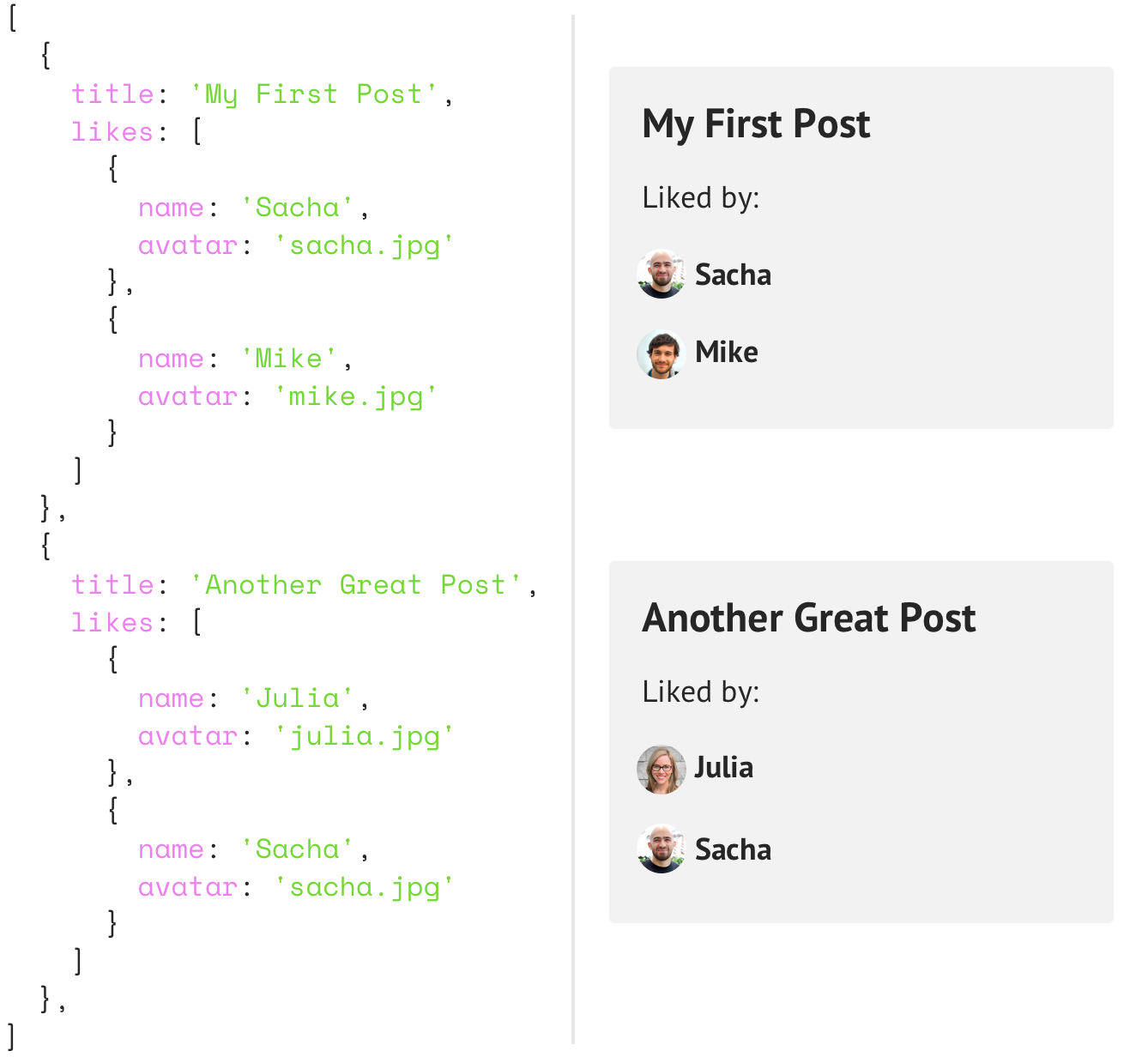
👏 La façon dont on demande les données est la façon dont on les reçoit.
{
"posts": [
{
"title": "First post",
"likes": [
{
"name": "Liker 1",
"avatar": "avatar1.jpg"
},
{
"name": "Liker 2",
"avatar": "avatar2.jpg"
}
]
},
{
"title": "Second post",
"likes": [
{
"name": "Forever alone",
"avatar": "avatar3.jpg"
}
]
}
]
}Les champs d'une query supportent des arguments. Par exemple, si on veut afficher un article spécifique, on peut ajouter un argument id au champ posts :
query getFirstPost {
posts(id: "1"){
title
body
author {
name
avatar
profileUrl
}
}
}✌️L'ajout d'arguments va nous permettre d'affiner nos requêtes, de filtrer, trier, paginer...
ℹ️ Il est possible d'ajouter un nom à notre query, pratique pour l'analytics.
REST
GraphQL
----------------------------------- request
GET /posts/123 HTTP 1.1
Host: http://rest.acme.com/
----------------------------------- response
HTTP/1.1 200 OK
Content-Type: application/json
{
"id:" 123,
"body": "Lorem Ipsum dolor sit",
"user_id": 456,
"views": 45,
"date": "2017-07-14T12:44:17.449Z"
// etc.
}----------------------------------- request
POST / HTTP 1.1
Host: http://graphql.acme.com/
Content-Type: application/graphql
{
post(id: 123) {
id
body
date
}
}
----------------------------------- response
HTTP/1.1 200 OK
Content-Type: application/json
{
"data": {
"post": {
"id:" "123",
"body": "Lorem Ipsum dolor sit",
"date": "2017-07-14T12:44:17.449Z"
}
}
}Démo
Si vous êtes absent de la présentation, essayez donc la version 4 de l'API GitHub, propulsée par GraphQL !
Pensez en terme de graph...
Query (Lecture)
Mutation (Écriture)
Subscription (Événement côté serveur)
Une implémentation GraphQL est organisée autour d'un schéma.
En voici les types racines :
Il est souvent utile de demander un schéma GraphQL pour des informations sur les requêtes qu'il supporte. C'est possible en utilisant le système d'introspection !
GraphQL Schema Language
type User {
id: ID!
name: String!
avatar: String
age: Int
type: UserRole!
createdAt: DateTime!
}
enum UserRole {
ADMIN
CONTRIBUTOR
}
# string containing DateTime.
scalar DateTime
# string containing HTML code.
scalar HTML
Modéliser un type
-
Par défaut les types présents sont : String, Int, Float, Boolean et ID.
-
Les champs obligatoires ont un point d'exclamation collé à leur type.
-
Utilisez enum pour restreindre les valeurs possibles.
🏅 Vous pouvez même définir vos propres types scalaires.
GraphQL Schema Language
# schema.graphql
enum VoteValue { YES NO }
type Vote {
voter: User!
contribution: Contribution!
value: VoteValue!
}
type Contribution {
title: String!
author: User!
votes(value: VoteValue): [Vote!]!
}
Modéliser les relations entre les types
-
Un type d'objet contient des champs, un par ligne. Chaque champ possède un nom et un type pouvant être soit un type d'objet, soit un type scalaire.
- Les champs d'objet peuvent avoir des paramètres, entre parenthèses. Ces paramètres sont également typés.
GraphQL Schema Language
# schema.graphql
type User {
name: String!
avatar: String!
}
type Post {
title: String!
likes: [User]
}
type Query {
posts(
# If omitted, returns all posts.
id: String
): [Post]
}
schema {
query: Query
}Modéliser ce qui est possible de demander
- On définit les types qui correspondent à nos données.
- On définit les champs demandables à la racine d'une query.
Implémentations GraphQL
La référence a été developpée pour Node.js.
var { graphql, buildSchema } = require('graphql');
var schema = buildSchema(`
type Query {
hello: String
}
`);
var resolvers = { hello: () => 'Hello world!' };
graphql(schema, '{ hello }', resolvers).then((response) => {
console.log(response);
});



Implémenter un resolver 1/2
Un resolver est une fonction qui permet de résoudre un champ GraphQL.
- obj : L'objet précédent (absent pour un resolver racine).
- args : Les arguments pour le champ.
- context : Le context partagé par tous les resolveurs pour contenir les informations partagées (l'utilisateur courant, la connexion à la BDD, …).
const resolvers = {
Query: {
user(obj, args, context) {
// Votre code pour récupérer un utilisateur
return context.db.loadUserByID(args.id);
}
}
}
Implémenter un resolver 2/2
const resolvers = {
Query: {
user(obj, args, context) {
return context.db.loadUserByID(args.id);
}
},
User: {
name(obj, args, context) {
return obj.name;
}
avatar(obj, args, context) {
return context.generateAvatarUrl(obj.avatar);
}
}
}
Maintenant qu'un objet User est disponible, GraphQL va continuer son execution afin de résoudre les champs demandés.
On explique ici, comment récupérer name et avatar.
GraphQL Relay Specification
Global Object Identification
Connections
Input Object Mutations
Un lot de 3 conventions supplémentaires à adopter sur un serveur GraphQL
Global Object Identification
# An object with an ID
interface Node {
# The id of the object.
id: ID!
}
type User implements Node {
id: ID!
name: String
}
type Vote implements Node {
id: ID!
voter: User!
}type Query {
# Fetches an object given its ID
node(
# The ID of an object
id: ID!
): Node
}
1. Une interface Node.
2. Le champ node à la racine du type Query.
En gros associer un id unique à chaque objet afin de pouvoir l'identifier et le récupérer à nouveau indépendamment de son type.
💡 Surtout utile pour les clients GraphQL.
Pagination
La pagination par curseur est la méthode de pagination la plus efficace et doit toujours être utilisée dans la mesure du possible.

Le pattern Connection
- La possibilité de paginer une liste.
- La possibilité de demander des informations sur la connection elle-même comme le nombre total d'éléments ou est-ce qu'il y a des éléments avant ou après.
- La possibilité de demander des informations sur les liaisons, comme le curseur ou des champs supplémentaires.
- Fournir des curseurs opaques.
Adopter Connection est une bonne pratique qui permet de d’intégrer notre API directement dans les clients GraphQL, en partageant un format commun.
Démonstration
du pattern Connection
L'implémentation est un peu longue...
Les plus courageux la trouveront à la suite des slides !
⬇️
# Information about pagination in a connection.
type PageInfo {
# When paginating forwards, are there more items?
hasNextPage: Boolean!
# When paginating backwards, are there more items?
hasPreviousPage: Boolean!
# When paginating backwards, the cursor to continue.
startCursor: String
# When paginating forwards, the cursor to continue.
endCursor: String
}1. On ajout un objet PageInfo à notre schéma
Au sein de la connection, il nous permettra de récupérer toutes les informations nécessaires ! 👌
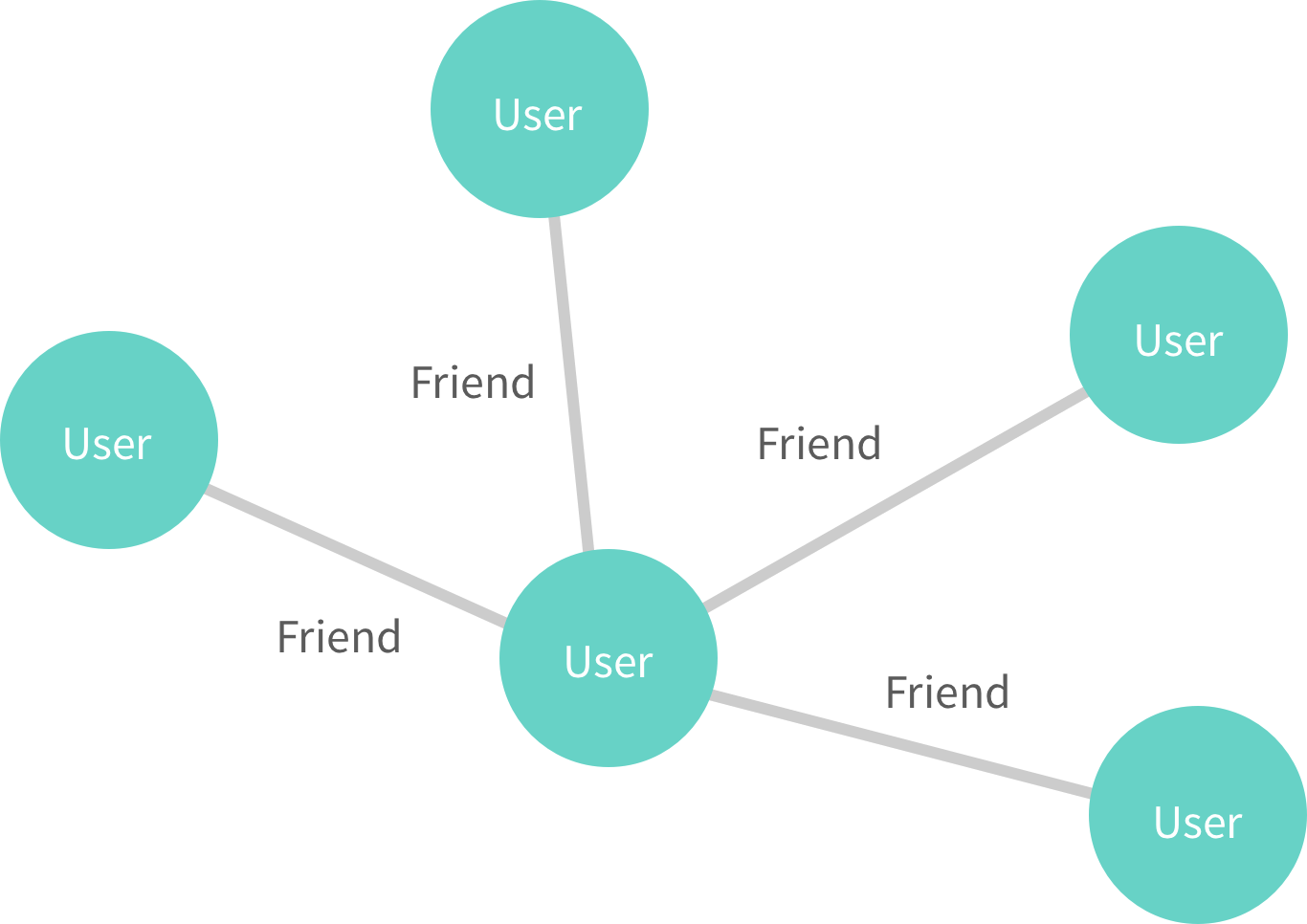

UserFriendsEdge représente la ligne qui connecte 2 noeuds User !
type UserFriendsEdge {
cursor: String!
node: User
friendedAt: DateTime
}
type User implements Node {
id: ID!
name: String
}User est un noeud de notre graph.
type FriendsConnection {
totalCount: Int!
pageInfo: PageInfo!
edges: [UserFriendsEdge]
}
type User {
id: ID!
name: String!
friendsConnection(
# Returns the elements that come after the specified cursor.
after: String
# Returns the first n elements from the list.
first: Int
# Returns the elements that come before the specified cursor.
before: String
# Returns the last n elements from the list.
last: Int
): FriendsConnection!
}
2. On crée la nouvelle Connection et on l'ajoute à User
Utiliser notre Connection
{
user {
name
friendsConnection(first:2 after:"Y3Vyc29yMQ=="){
totalCount
edges {
node {
name
}
cursor
}
pageInfo {
endCursor
hasNextPage
}
}
}
}{
"data": {
"user": {
"name": "R2-D2",
"friendsConnection": {
"totalCount": 3,
"edges": [
{
"node": {
"name": "Han Solo"
},
"cursor": "Y3Vyc29yMg=="
},
{
"node": {
"name": "Leia Organa"
},
"cursor": "Y3Vyc29yMw=="
}
],
"pageInfo": {
"endCursor": "Y3Vyc29yMw==",
"hasNextPage": false
}
}
}
}
}On va récupérer les 2 amis d'R2-D2 après C-3PO dont le curseur est "Y3Vyc29yMQ=="
Mutation
input PostInput {
title: String
}
type Post {
id: ID!
title: String
}
type Mutation {
createPost(input: PostInput): Post
updatePost(id: ID!, input: PostInput): Post
}
schema {
mutation: Mutation
}Créer et modifier façon GraphQL
1. On définit les inputs qui correspondent aux données à transmettre.
2. On définit les mutations possibles, ainsi que les données qu'on souhaite retourner du serveur qui composent le type de retour.
Designer des mutations pérennes... 🚀
-
Nommer. Commencer par un verbe (create, update, delete, like, reload…) suivi du sujet.
-
Spécificité. Faire des mutations spécifiques qui correspondent aux actions sémantiques de l'utilisateur.
-
Input object. Utiliser un input de type objet unique, requis, comme seul argument.
-
Payload. Utiliser un type unique pour chaque mutation et ajouter la sortie de la mutation en tant que champ(s) à ce type.

type Post {
id: ID!
title: String
}
input CreatePostInput {
title: String!
}
type CreatePostPayload {
# The post that was created. It is nullable to handle errors.
post: Post
}
input UpdatePostInput {
postId: ID!
newTitle: String!
}
type UpdatePostPayload {
# The updated post. Nullable for the same reason as before.
post: Post
}
type Mutation {
createPost(input: CreatePostInput!): CreatePostPayload
updatePost(input: UpdatePostInput!): UpdatePostPayload
}type Subscription {
userLikedPost(postId: ID!): User
}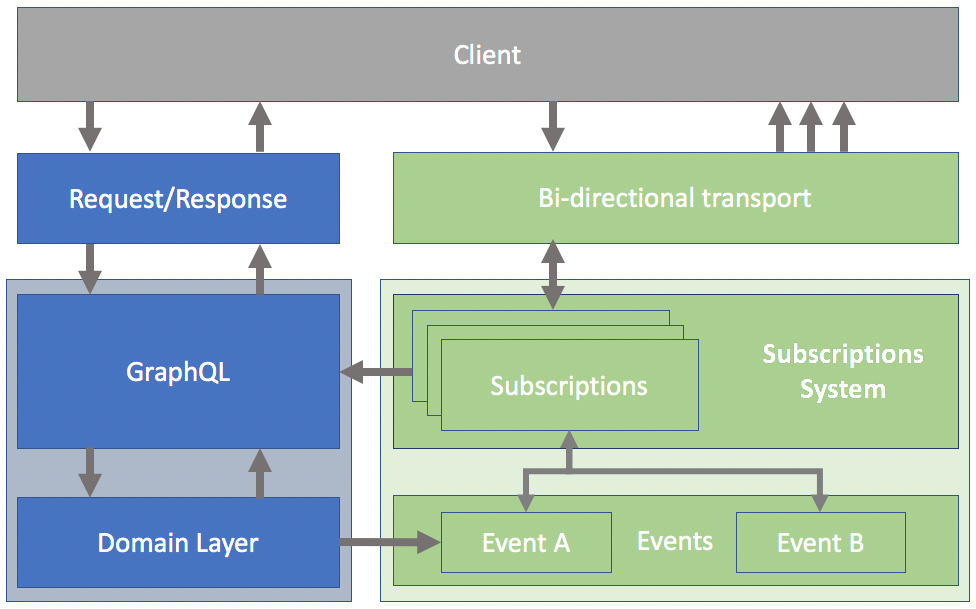
Ajouter une couche de temps réel avec les Subscriptions
Le client s'inscrit à des évènements spécifiques, puis reçoit les données demandées en temps réel, généralement implémentées en websockets.
Prêt à mettre en prod ?
Une petite minute...
🤔 Cache, sécurité, versioning et documentation
Versionning
Dès son introduction GraphQL a été décrit comme étant Version Free.
La forme des réponses étant déterminée entièrement par la requête des clients. Ajouter de nouvelles fonctionnalités ou champs, n'affecte pas les clients existants.
L'approche recommandée est add-only afin de faire évoluer le schema en préservant les comportements actuels.
Versioning
On peut déprécier un champ, c'est facile pour un champ nullable, en revanche un champ requis se doit d'être toujours supporté.
Le pragmatisme m'incite à utiliser un schéma non public, le temps de stabiliser la structure et la dénomination des types et des champs.
La spécification Relay est un moyen d'éviter les BCs mais ça ne fait pas tout : à vous d'anticiper les évolutions !
Facebook prend pour exemple son propre schéma GraphQL comprenant plus de 1 000 types qui supporte toujours des applications iOS et Android datant de plus de 4 ans. (Source)
Cache coté client : Éviter de demander à nouveau, si la ressource n'a pas expiré, via une date d'expiration ou un système de tag.
Cache réseau : Intercepter les requêtes pour éviter d'appeler le serveur applicatif (HIT/MISS), exemple Varnish.
Cache applicatif : Rendre des réponses plus rapides à générer en stockant le résultat de requêtes en BDD, exemple Redis.
3 types de cache
GraphQL et le cache
Le type de cache recommandé est applicatif.


Une requête GraphQL peut être écrite de différentes façons et demander les mêmes données.
La même URL est appelée pour différentes requêtes, produisant différents résultats rendant le cache réseau plus difficilement applicable.
DataLoader
Cache : au sein d'une même requête conserver en mémoire, le résultat d'un travail pour éviter de le dupliquer.
Un utilitaire pour du cache applicatif
⚠️ Utile pour optimiser les requêtes imbriquées... Mais ne fera pas tout le travail à votre place !
Traitement par lots : au sein d'une même requête, permettre d'exécuter une opération en lots au lieu de nombreuses petites recherches.
Sécurité
Authentification et Validation❓
C'est vraiment indépendant de GraphQL, vous pouvez effectuer les vérifications librement au sein des resolvers racines par exemple.

Sécurité
⚠️ Attaques par déni de service ⚠️
Envoyer une requête complexe peut consommer trop de ressources, par exemple : user ➡️ friends ➡️ friends …
Un moyen de s'en prévenir est de faire une analyse de coût avant de l'exécuter et d'imposer une limite.
Au niveau des resolvers on peut également sécuriser les arguments, par exemple ne jamais récupérer plus de 50 éléments dans une liste même si l'utilisateur en demande 1000.
Sécurité
Si votre endpoint GraphQL n'est utile qu'à vos propres clients (Web et mobile), vous pouvez lister les différentes requêtes utilisées...
On peut donc utiliser une liste blanche afin d'approuver uniquement les requêtes que vous utilisez. ✅
ℹ️ C'est l'approche que Facebook semble utiliser…
Documentation
Génération automatique à partir du schéma
GraphQL pour les développeurs frontend
Permet à chaque composant de décrire ses propres dépendances de données.
Gestion des erreurs, des mutations optimistes.
✅ Permet du cache côté client.

-
Alternative à REST
-
Optimise la taille des échanges réseau
-
Facilite la description des exigences en matière de données côté frontend
-
Simplifie l'organisation du code côté backend
-
Met en avant le cache applicatif plus que le cache réseau

-
Mise en place rapide
-
Pratique pour les tests fonctionnels
-
Le code frontend est grandement allégé, car la récupération des données est automatique.
- S'intègre rapidement à un projet existant, en facilitant sa refactorisation.
- Notre API n'est pas (encore) ouverte au public, le temps de travailler la performance et la sécurité.
GraphQL un retour personnel
Merci ! Questions ?
On travaille dur pour mettre à jour la démocratie... Vous nous donnez un coup de pouce (en GraphQL) ? 👍
Slides: spyl.net/slides/parisweb-2017