UNE API GRAPHQL: DU HYPE À LA PROD
@spyl94 ~ Aurélien David



GraphQL ?
GraphQL est une syntaxe qui décrit comment demander des données.
Uniquement la couche transport de l'API.
Langage de requête de base de données.
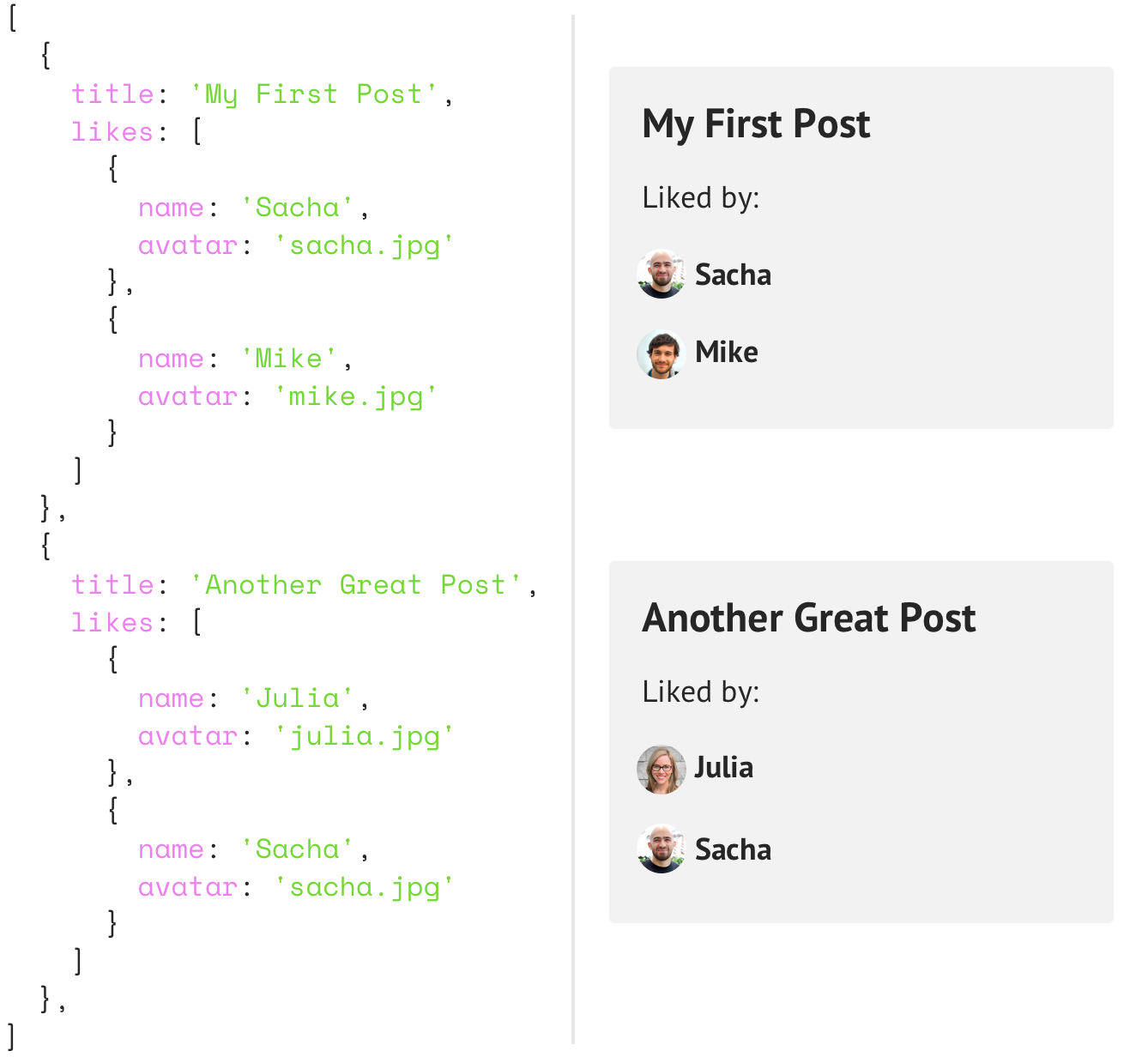
Problème concret avec REST
Ajouter la liste d'utilisateurs ayant aimé des articles de blog.
Notre approche est de modifier l'endpoint /posts et de lui ajouter pour chaque article la liste d'utilisateurs ayant aimés.

Problème: l'application mobile est beaucoup plus lente à charger… sans avoir besoin des likes !
Solution 1: On ajoute un nouveau endpoint GET /posts/{id}/likes
😡 Une requête en plus pour chacun des articles.
Solution 2: On ajoute un nouveau endpoint GET /posts_with_likes
😡 Un endpoint desktop, un endpoint mobile, pas scalable...
Solution 3: On utilise une option du type ?fields=title,likes
😒 Complexifie l'implémentation, augmente le taux de MISS cache.
Une approche différente de concevoir une API
Au lieu d'avoir plusieurs endpoints «stupides», disposer d'un seul endpoint «intelligent» qui peut prendre des requêtes complexes, puis formatter la sortie de données sous quelque forme que ce soit.

GraphQL est utilisé depuis plus de quatre ans chez Facebook en production et a beaucoup évolué avant d'être ouvert à tous.
REST
GraphQL
Trois appels à trois destinataires différents.
- “Mon linge propre“
- “Une margherita“
- “Une douzaine d'oeufs“
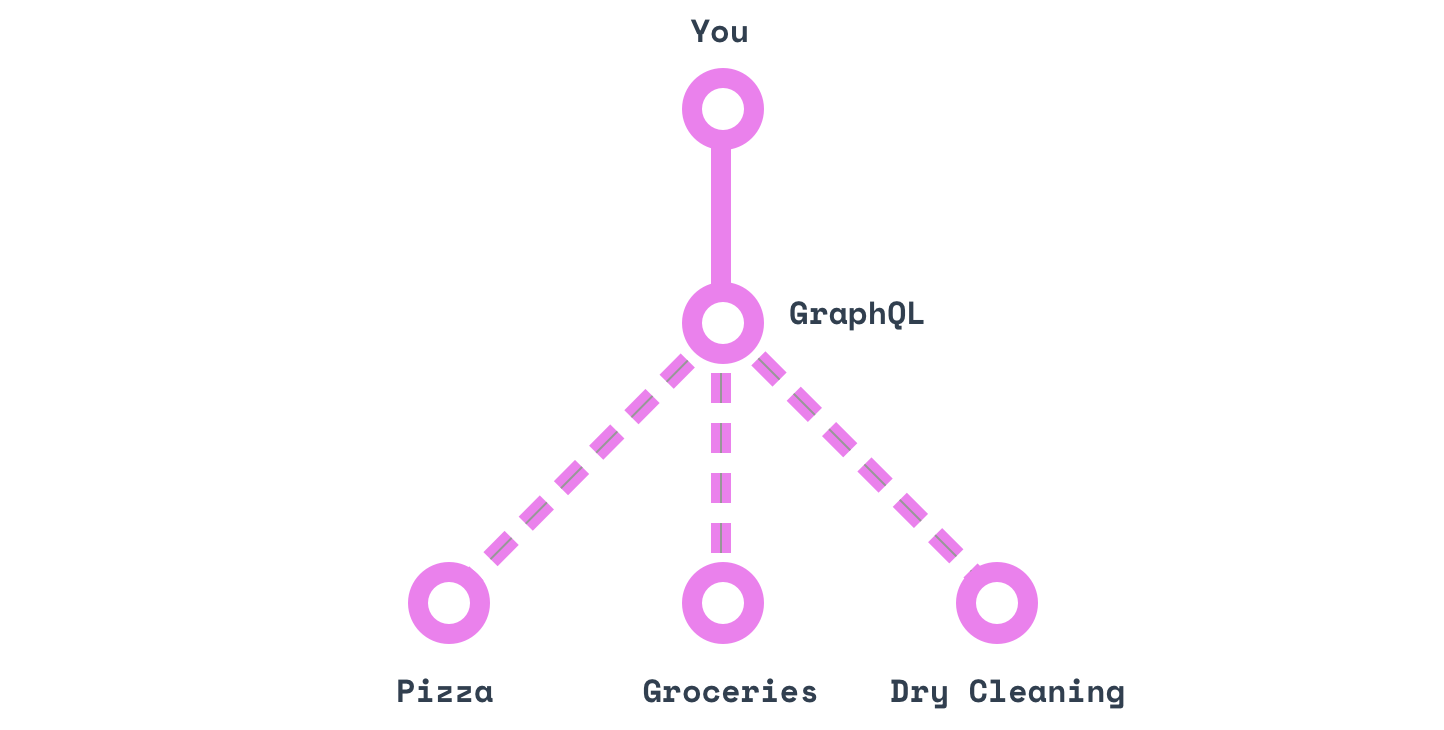
Un seul appel pour demander ce qu'on veut.
“Donne moi mon linge propre, une margherita et une douzaine d'oeufs.”
En d'autres termes, GraphQL établit un language pour parler à un assistant personnel magique.

Permet au client de préciser les données dont il a besoin.
Facilite l'agrégation des données de plusieurs sources.
Utilise un système de type pour décrire les données.
La requête que l'on fait à notre assistant personnel GraphQL est appelée une query, ça ressemble à ça :
query {
posts {
title
likes {
name
avatar
}
}
}
POST
/graphql➡️
👏 La façon dont on demande les données est la façon dont on les reçoit.
{
"posts": [
{
"title": "First post",
"likes": [
{
"name": "Liker 1",
"avatar": "avatar1.jpg"
},
{
"name": "Liker 2",
"avatar": "avatar2.jpg"
}
]
},
{
"title": "Second post",
"likes": [
{
"name": "Forever alone",
"avatar": "avatar3.jpg"
}
]
}
]
}Les champs d'une query supportent des arguments. Par exemple, si on veut afficher un article spécifique, on peut ajouter un argument id au champ posts:
query getFirstPost {
posts(id: '1'){
title
body
author {
name
avatar
profileUrl
}
}
}query getPostById ($id: String!) {
posts(id: $id){
title
body
author {
name
avatar
profileUrl
}
}
}✌️L'ajout d'arguments va nous permettre d'affiner nos requêtes, de filtrer, trier, paginer...
ℹ️ Il est possible d'ajouter un nom à notre query, pratique pour l'analytics.
Démo
Pensez en terme de graph...
Query (Lecture)
Mutation (Ecriture)
Subscription (Evénement côté serveur)
Une implémentation GraphQL est organisée autour d'un schéma.
En voici les types racines:
Il est souvent utile de demander un schéma GraphQL pour des informations sur les requêtes qu'il supporte. C'est possible en utilisant le système d'introspection !
GraphQL Schema Language
# schema.graphqls
type User {
name: String!
avatar: String!
}
type Post {
title: String!
likes: [User]
}
type Query {
posts(
# If omitted, returns all posts.
id: String
): [Post]
}
schema {
query: Query
}Modéliser ce qui est possible de demander
- On définit les types qui correspondent à nos données.
- On définit les champs demandables à la racine d'une query.
Et PHP dans tout ça…
webonyx/graphql-php, l'implémentation de la spécification GraphQL.
overblog/GraphQLBundle, bundle Symfony permettant :
- de définir son schéma en YAML
- de créer l'endpoint /graphql
- d'ajouter GraphiQL

# src/AppBundle/Resources/config/graphql/Query.types.yml
#
# type Query {
# posts(id: String): [Post]
# }
#
Query:
type: object
config:
fields:
posts:
type: "[Post]"
args:
id:
description: "If omitted, returns all posts."
type: "String"
resolve: "@=resolver('posts', [args])"Implémenter le schema GraphQL 1/2
🤔 Notez la clé supplémentaire resolve qui va nous permettre d'expliquer comment trouver la liste des articles.
On traduit notre schéma en YAML.
# src/AppBundle/Resources/config/graphql/Post.types.yml
Post:
type: object
config:
fields:
id:
type: "String!"
title:
type: "String!"
likes:
type: "[User]"
resolve: "@=resolver('post_likes', [value])"Implémenter le schema GraphQL 2/2
# src/AppBundle/Resources/config/graphql/User.types.yml
User:
type: object
config:
fields:
name:
type: "String!"
avatar:
type: "String!"🤔 On ajoute resolve au champ likes pour expliquer comment trouver les utilisateurs ayant aimés l'article.
Implémenter nos resolver 1/3
use Overblog\GraphQLBundle\Definition\Argument;
use AppBundle\Entity\Post;
class PostResolver
{
public function get(Argument $argument) /* resolver posts */
{
$repo = // on récupère le repository des posts
if ($argument->offsetExists('id')) {
return [ $repo->find($argument->offsetGet('id')) ];
}
return $repo->findAll();
}
public function getLikes(Post $post) /* resolver post_likes */
{
$repo = // on récupère le repository des utilisateurs
return $repo->getUsersWhoLikedPost($post);
}
}Un resolver est une fonction qui permet de résoudre un champ GraphQL.
Implémenter nos resolver 2/3
services:
resolver.posts:
class: AppBundle\GraphQL\PostResolver
tags:
- { name: overblog_graphql.resolver, alias: "posts", method: "get" }
- { name: overblog_graphql.resolver, alias: "post_likes", method: "getLikes" }On a défini notre schéma ainsi que l'implémentation du resolver, il ne nous manque plus qu'à faire la liaison.
Et voilà notre implémentation est prête !

Implémenter nos resolver 3/3
💡 Le bundle utilise alors le composant PropertyAccess de Symfony, pour ne pas nous obliger à définir un resolver !
On n'a pas fait de résolver pour les champs name, avatar ou encore title.
Ces champs ont un nom identique dans le schéma à leur implémentation, on parle alors de resolvers triviaux.
Prêt à mettre en prod ?
Une petite minute...
Cache coté client: Eviter de demander à nouveau, si la ressource n'a pas expiré, via une date d'expiration ou un systême de tag.
Cache réseau: Intercepter les requêtes pour éviter d'appeler le serveur applicatif (HIT/MISS), exemple Varnish.
Cache applicatif: Render des réponses plus rapides à générer en stockant le résultat de requêtes en BDD, exemple Redis.
3 types de cache
GraphQL et le cache
Le type de cache recommandé est applicatif.


Une requête GraphQL peut être écrite de différentes façons et demander les mêmes données.
La même URL est appelé pour différentes requêtes, produisant différents résultats rendant le cache réseau difficilement applicable.
DataLoader
Cache : au sein d'une même requête conserver en mémoire, le résultat d'un travail pour éviter de le dupliquer.
Un utilitaire pour du cache applicatif
L'utilisation d'overblog/dataloader-bundle est particulièrement utile pour optimiser les requêtes imbriquées.
Traitement par lots : au sein d'une même requête, permettre d'executer une opération en lots au lieu de nombreuses petites recherches.
GraphQL pour les développeurs frontend
Permet à chaque composant de décrire ses propres dépendances de données.
Gestion des erreurs, des mutations optimistes.
Permet du cache côté client.

Mutation
input PostInput {
title: String
}
type Post {
id: String!
title: String
}
type Mutation {
createPost(input: PostInput): Post
updatePost(id: String!, input: PostInput): Post
}
schema {
mutation: Mutation
}Créer et modifier façon GraphQL
Subscription (RFC)
type Subscription {
userLikedPost(postID: String): User
}😢 Pas encore implémenté par webonyx/graphql-php
Une piste d'implémentation.
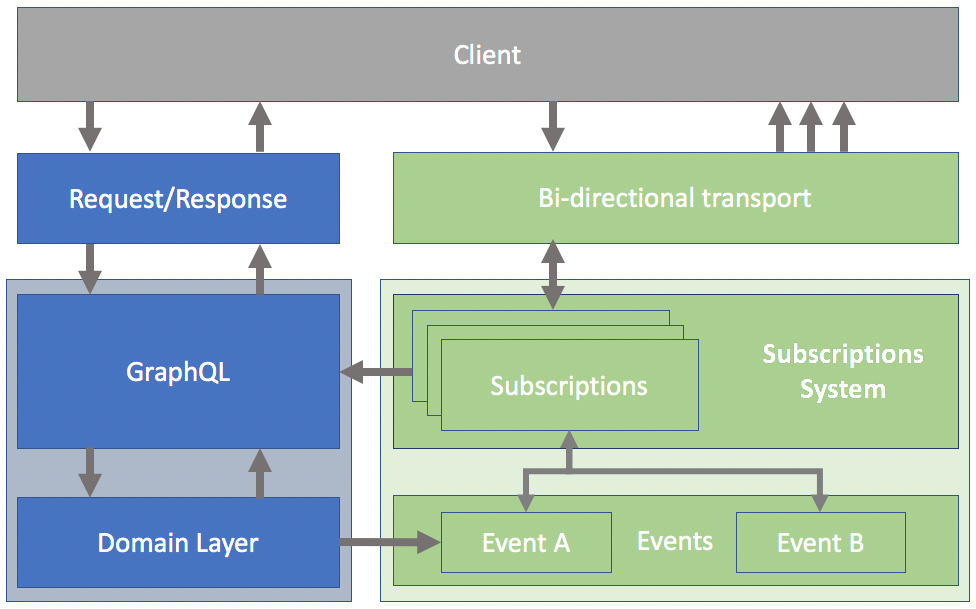
Ajouter une couche de temps réel
-
Alternative à REST
-
Optimise la taille des échanges réseau
-
Facilite la description des exigences en matière de données côté frontend
-
Simplifie l'organisation du code côté backend
-
Met en avant le cache applicatif plus que le cache réseau

-
Ne plus utiliser les groupes de serialization est un plaisir !
- Le code frontend est grandement allégé, car la récupération des données est automatique.
- S'intègre rapidement à un projet existant, en facilitant sa refactorisation.
- API non ouverte au public, le temps de travailler les performances.
GraphQL un retour personnel
Merci ! Questions ?
On travaille dur pour mettre à jour la démocratie... Vous nous donnez un coup de pouce ? 🙏
Slides: spyl.net/slides/phptour-2017