GraphQL brings challenges and opportunities
@spyl94 ~ Aurélien David



GraphQL ?
GraphQL is a syntax that describes how to request data.
Only the transport layer of an API.
Database query language.
A different approach to designing an API
Instead of having several "stupid" endpoints, have a single "smart" endpoint that can take complex queries, and then format the output of data in any form.

GraphQL has been used for more than four years at Facebook in production.
A GraphQL request is called a query and looks like this:
query {
posts {
title
likes {
name
avatar
}
}
}
POST
/graphql➡️
👏 The way we ask for the data is the way we receive it.
{
"posts": [
{
"title": "First post",
"likes": [
{
"name": "Liker 1",
"avatar": "avatar1.jpg"
},
{
"name": "Liker 2",
"avatar": "avatar2.jpg"
}
]
},
{
"title": "Second post",
"likes": [
{
"name": "Forever alone",
"avatar": "avatar3.jpg"
}
]
}
]
}A query support arguments. For example, if you want to display a specific article, you can add an id argument to the posts field:
query getFirstPost {
posts(id: "1"){
title
body
author {
name
avatar
profileUrl
}
}
}✌️Adding arguments will allow us to refine our queries, filter, sort, page ...
ℹ️ It's possible to add a name to a query, also convenient for analytics.
GraphQL Schema Language
# schema.graphql
type User {
name: String!
avatar: String!
}
type Post {
title: String!
likes: [User]
}
type Query {
posts(
# If omitted, returns all posts.
id: ID
): [Post]
}
schema {
query: Query
}Thinking in graph…
- We define the types that correspond to our data.
- We define the requestable fields at the root of a query.
Let's talk about what people don't tell you about GraphQL…
Versionning
Since its introduction GraphQL has been described as Version Free.
The shape of the returned data is determined entirely by the client's query, so servers become simpler and easy to generalize. When you're adding new product features, additional fields can be added to the server, leaving existing clients unaffected.
The recommended approach is add-only in order to change the schema by preserving current behaviors.
Versioning
You can depreciate a field, it's easy for a nullable one, but a required field must always be supported.
Pragmatism makes me use a non-public schema, in order to stabilize the structure and naming of types and fields.
Facebook takes as an example its own GraphQL schema with more than 1,000 types that still supports iOS and Android applications over 4 years old. (Source)
GraphQL Relay Specification
Global Object Identification
Connections
Input Object Mutations
A set of 3 additional conventions to adopt on a GraphQL server
💡 By using it, you will avoid BCs but it's still your job to anticipate the evolutions!
GraphQL and caching
The recommended cache level is application.

A GraphQL query can be written in different ways and asked for the same data.
The same URL is called for different queries, producing different results, making the network cache more difficult to apply.
network cache
Security
Authentication and Authorization❓
Security really independent of GraphQL.
For example you can perform the checks in your code within root resolvers.
You can also mark each fields of your schema as public or not, depending on the viewer.

As someone is going to ask it later, let's answer this question right now.
Security
⚠️ Denial of service attacks ⚠️
Sending a complex query can consume too many resources, for example: user ➡️ friends ➡️ friends …
One way to prevent this is, to do a cost analysis before the execution and by imposing a limit.
At the resolver level, you can also secure the arguments. For example never recovering more than 100 elements in a list even if users ask for 5000.
Security
If your GraphQL endpoint is only useful for your own clients (web and mobile), you can list the different queries used ...
And then create a whitelist ✅
ℹ️ This approach may be used by Facebook...
Monitoring
REST


GraphQL

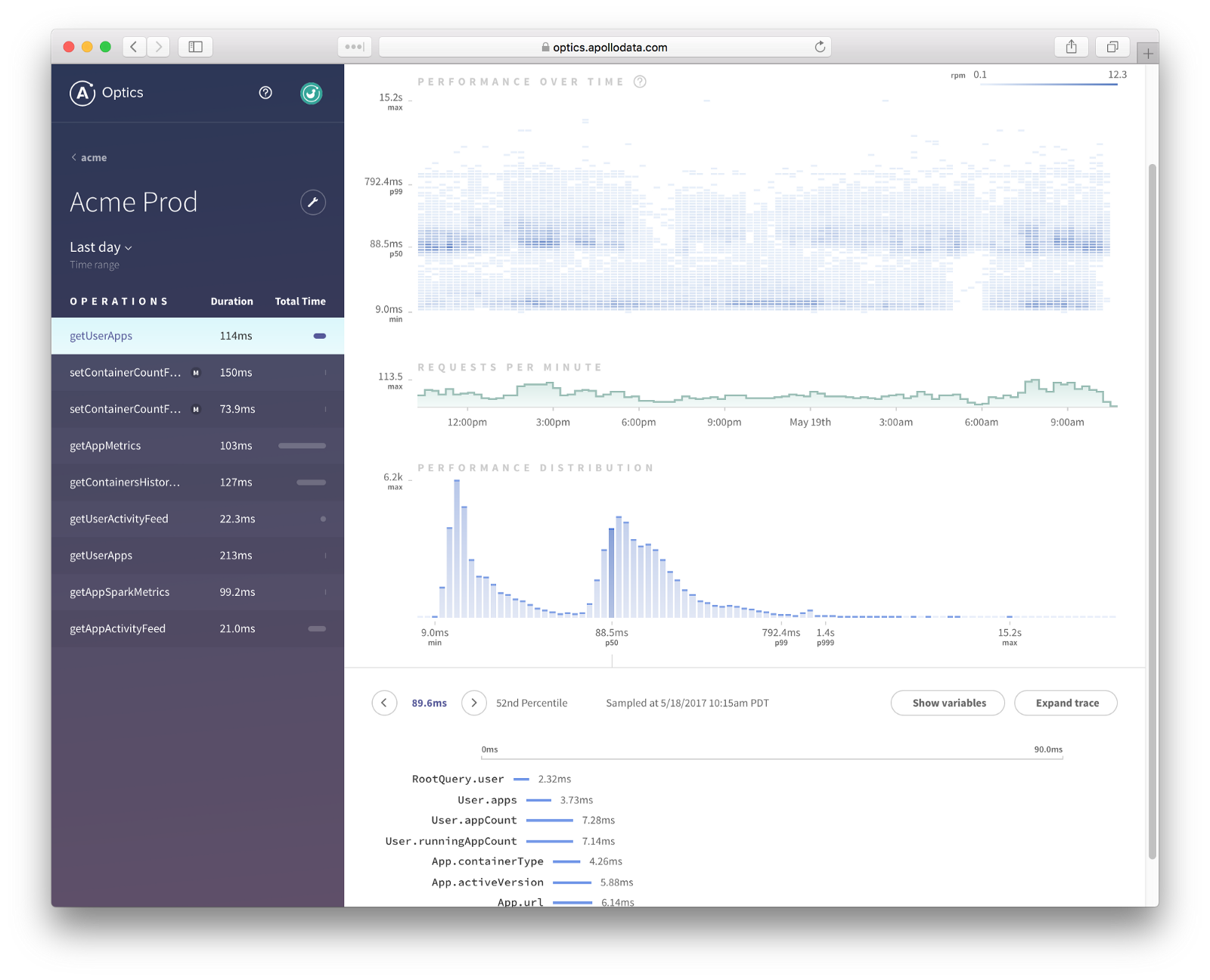
Apollo Engine
Apollo Analytics
Documentation
Generated by the schema

-
Quick to proof of concept, just try it !
-
Integrates well in front of your legacy code.
-
Frontend devs love it !
- Needs important work before using it as an official public API, but GitHub is doing it.
Year + 1: GraphQL personal feedback
Thanks ! Any questions ?
We work hard to update our democracy (with GraphQL)… 👍