A GraphQL API: from hype to production




Aurélien David


collective intelligence generator
We use GraphQL in production for :
- Consultation
- Participatory Budget
- Call for projects

GraphQL ?
GraphQL is a syntax that describes how to request data.
Only the transport layer of an API.
Database query language.
Let's start with a REST problem
[New feature] Diplaying the list of users who ❤️ a blog post.
We update our /posts endpoint, adding a likes key. For each user, we give its name and avatar.

GET
/posts
➡️
[
{
"title": "My first post",
"likes": [
{
"name": "Sacha",
"avatar": "sacha.jpg"
},
{
"name": "Mike",
"avatar": "mike.jpg"
}
]
},
{
"title": "Another great post",
"likes": []
}
]Problem: our mobile application is much slower to load… and we don't even care about the likes feature on mobile !
Solution 1: We add a new endpoint GET /posts/{id}/likes
😡 One more HTTP request for each post.
Solution 2: We add a new endpoint GET /posts_with_likes
😡 A desktop endpoint, a mobile endpoint, not scalable…
Solution 3: We add an include option (REST++)
/posts?include=title&likes[avatar,name]
😒 Complex implementation, increase the rate of MISS cache.
A different approach to designing an API
Instead of having several "stupid" endpoints, have a single "smart" endpoint that can take complex queries, and then format the output of data in any form.

GraphQL has been used for more than five years at Facebook in production. It's an open standard since 2015.
REST
GraphQL
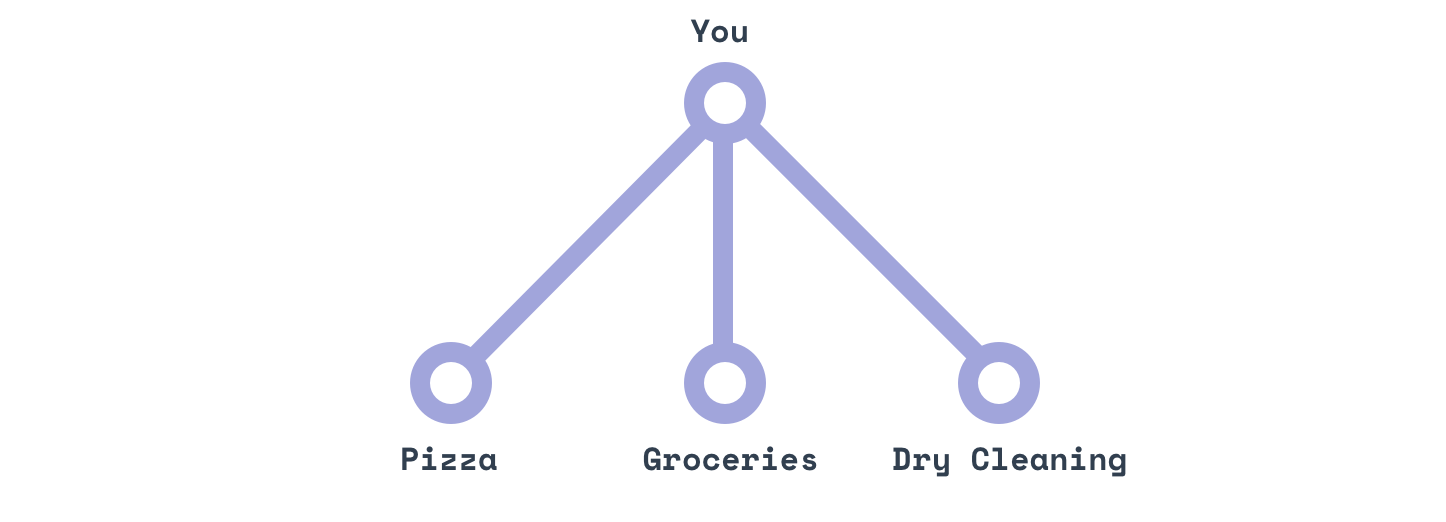
Three calls to three different recipients.
- “My clothes“
- “A margherita“
- “A dozen eggs“
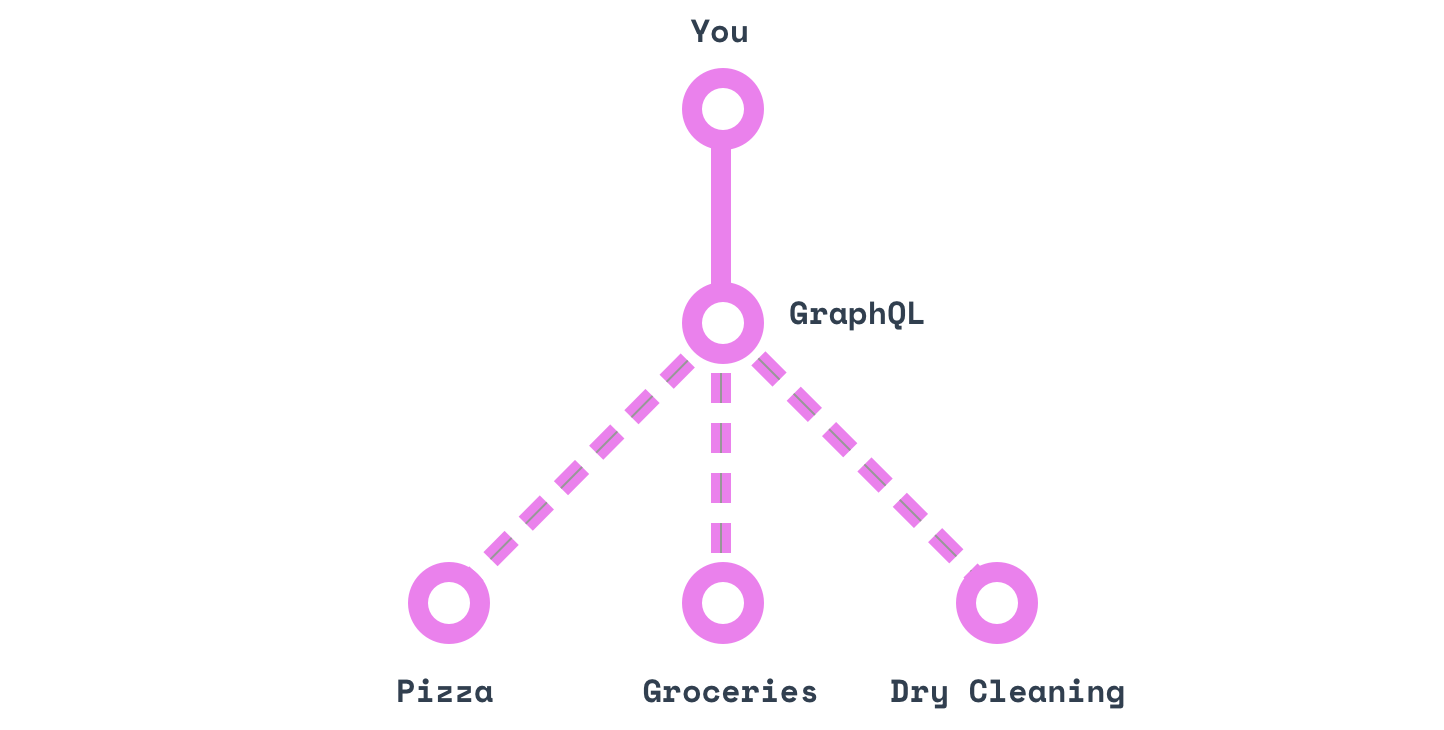
One call to ask what you want.
“Give me my clean linen, a margherita and a dozen eggs.”
In other words, GraphQL establishes a language to speak to a magical personal assistant.

Allows the client to ask what he wants.
Easily aggregate data from multiple sources.
Uses a type system to describe the data.
A GraphQL request is called a query and looks like this:
query {
posts {
title
likes {
name
avatar
}
}
}
POST
/graphql➡️
👏 The way we ask for the data is the way we receive it.
{
"data": {
"posts": [
{
"title": "My first post",
"likes": [
{
"name": "Sacha",
"avatar": "sacha.jpg"
},
{
"name": "Mike",
"avatar": "mike.jpg"
}
]
},
{
"title": "Another great post",
"likes": []
}
]
}
}A query support arguments. For example, if you want to display a specific article, you can specify an id argument to the post field:
query getFirstPost {
post(id: "1"){
id
title
body
comments(first: 2) {
content
}
}
}✌️Adding arguments will allow us to refine our queries, filter, sort, page ...
ℹ️ It's possible to add a name to a query, convenient for monitoring.
{
"data": {
"post": {
"id": "1",
"title": "First post",
"body" "Content",
"comments": [
{ "content" "Amazing" },
{ "content" "Great !" }
]
}
}
}Thinking in graph...
Query (Read)
Mutation (Write)
Subscription (Server-side events)
A GraphQL implementation is organized around a schema.
Here are the root types:
GraphQL Schema Language
# schema.graphql
type User {
name: String!
avatar: String
}
type Post {
title: String!
likes: [User]!
}
# Entrypoint
type Query {
posts: [Post]
post(id: ID!): Post
}Step 1: We define the types that correspond to our data.
Step 2: We define the Query type that represent the requestable fields at the root of a query.
Designing Your Schema
Where is my PHP code ?
webonyx/graphql-php: an implementation of the GraphQL spec.
overblog/GraphQLBundle: my favorite Symfony bundle :
- define your schema in YAML
- create a /graphql endpoint

# Query.types.yml
Query:
type: object
config:
fields:
posts:
type: "[Post]"
resolve: "@=resolver('allPosts')"
post:
type: "Post"
args:
id:
type: "String!"
resolve: "@=resolver('postById', [args['id']])"# Post.types.yml
Post:
type: object
config:
fields:
title:
type: "String!"The resolve key explains how to call our resolver function with ExpressionLanguage.
| resolver(string $alias, array $args = []) |
🤔 allPosts and postById are aliases that we will use later.
During the execution phase the bundle will use the PropertyAccess component, so you don't have to explain how to retrieve the value of trivial fields !
Let's translate our schema in YAML with GraphQLBundle
services:
graphql.resolver.post:
class: AppBundle/GraphQL/Resolver/PostResolver
arguments:
- "@repository.post"
tags:
- { name: overblog_graphql.resolver, alias: "allPosts", method: "resolveAll" }
- { name: overblog_graphql.resolver, alias: "postById", method: "resolvePostById" }class PostResolver
{
// Injected repository, etc...
public function resolveAll(): Collection
{
return $this->postRepository->findAll();
}
public function resolvePostById(string $postId): Post
{
return $this->postRepository->find($postId);
}
}A resolver is a function that resolve a GraphQL field.
We implement the resolvers
with our own business logic.
We defined our schema and the resolvers, all we need to do is link them.
services:
graphql.resolver.post:
tags:
# ...
- { name: overblog_graphql.resolver, alias: "postLikes", method: "resolveLikes" }class PostResolver
{
// previous content ...
public function resolveLikes(Post $post): Collection
{
return $this->userRepository->findUsersLikingPost($post);
}
}Let's implement our likes feature
# Post.types.yml
Post:
type: object
config:
fields:
# ...
likes:
type: "[User]!"
resolve: "@=resolver('postLikes', [value])"# User.types.yml
User:
type: object
config:
fields:
name:
type: "String!"
avatar:
type: "String"Our resolveLikes has access to the previous object which is a Post.
query {
post(id: "1") {
title
likes {
name
avatar
}
}
}run Query.post
Query execution — step by step
Execution starts at the top. Resolvers at the same level are executed concurrently.
Specification
PHP code (simplified)
run Post.title and Post.likes
run User.name and User.avatar (for each User returned in Post.likes)
Query
$post = resolvePostById("1");$title = $post->getTitle();
$likes = resolveLikes($post);$likes[0]->getName();
$likes[0]->getAvatar();
$likes[1]->getName();
$likes[1]->getAvatar();
…GraphQL Relay Specification
Global Object Identification
Connections
Input Object Mutations
A set of 3 additional conventions to adopt on a GraphQL server
OverblogGraphQLBundle has built-in support !
Mutation
input PostInput {
title: String
}
type Post {
id: ID!
title: String
}
type Mutation {
createPost(input: PostInput): Post
updatePost(id: ID!, input: PostInput): Post
}Create and update the GraphQL way
Step 1: We define the inputs that correspond to the data to be send.
Step 2: We define possible mutations and their return type.
mutation createPost(
$input: PostInput!
) {
post {
id
title
}
}{
input: {
title: "I <3 GraphQL"
}
}{
"data": {
"createPost": {
"post": {
"id": "1234",
"title": "I <3 GraphQL"
}
}
}
}
Using a mutation
Variables :
POST
/graphql➡️
Designing great mutations... 🚀
-
Naming. Start with a verb (create, update, delete, like, reload…) then the subject.
-
Specificity. Create a mutation for every semantic user actions.
-
Input object. Use a unique input type, required, as the only argument.
-
Payload. Use a unique payload type for every mutation and add the return data as fields of this type.

Let's implement the createPost mutation ! 1/3
# CreatePostInput.types.yml
CreatePostInput:
type: relay-mutation-input
config:
fields:
title:
type: "String!"input CreatePostInput {
title: String!
}# CreatePostPayload.types.yml
CreatePostPayload:
type: relay-mutation-payload
config:
fields:
post:
type: "Post"
type CreatePostPayload {
# The post that was created.
# It is nullable to handle errors.
post: Post
}Let's add our input type :
Let's add our payload type :
# Mutation.types.yml
Mutation:
type: object
config:
fields:
createPost:
builder: "Relay::Mutation"
builderConfig:
inputType: CreatePostInput
payloadType: CreatePostPayload
mutateAndGetPayload: "@=mutation('createPost', [value['title'], user])"type Mutation {
createPost(input: CreatePostInput!): CreatePostPayload
}Let's add createPost to the Mutation type :
Let's implement the createPost mutation ! 2/3
class PostMutation
{
public function create(string $title, User $user): array
{
$post = new Post();
$post->setAuthor($user);
$post->setTitle($title); // Use a form in real life !
// persist and flush
return ['post' => $post];
}
}graphql.mutation.post:
class: AppBundle\GraphQL\Mutation\PostMutation
tags:
- { name: overblog_graphql.mutation, alias: "createPost", method: "create" }Let's implement the createPost mutation ! 3/3
Production

A few things to think about before dumping REST for GraphQL…
Versionning
Since its introduction GraphQL has been described as Version Free.
The shape of the returned data is determined entirely by the client's query. When you're adding new product features, additional fields can be added to the server, leaving existing clients unaffected.
The recommended approach to schema evolution is add-only. This way we preserve current behaviors.
A nullable field is easy to deprecate, because you can resolve null.
A required field must always be supported , think twice before marking a field as required.
# Post.types.yml
Post:
type: object
config:
fields:
title:
type: "String"
name:
type: "String"
deprecationReason: "This field has been renamed to title."Just add a reason !
Deprecating a field
Facebook takes as an example its own GraphQL schema with more than 1,000 types that still supports iOS and Android applications over 4 years old. (Source)
Don't underestimate the time necessary to design a good contract. Especially since the names you choose will stay forever.
A Version Free API is hard…
…but possible!
💡 Using Replay Spec strictly should avoid most BCs but it's still your job to anticipate the evolutions.
Keep some schema bits internal while letting the rest public, to stabilize your structure and naming.
GraphQL and caching
The recommended cache level is application.

A GraphQL query can be written in different ways and asked for the same data.
The same URL is called for different queries, producing different results, making the network cache more difficult to apply.
network cache
DataLoader
Caching : within the same query, keep in memory the result of a job to avoid duplicating it.
A tool for application cache
⚠️ Useful for optimizing nested queries ... But will not do all the performance work for you!
Batching : within a single query, allow you to run a batch operation instead of many small searches.

Security
Authentication and Authorization❓
💡 The bundle provides some helpers for access control and public visibility.

# Post.types.yml
Post:
type: object
config:
fields:
id:
type: "ID!"
access: "@=hasRole('ROLE_USER')"
topSecretField:
type: "String!"
public: "@=hasRole('ROLE_SUPER_ADMIN')"Security is independent of GraphQL.
Security
⚠️ Denial of service attacks ⚠️
Sending a heavy query can consume too many resources, for example: user ➡️ friends ➡️ friends ➡️ friends …
One way to prevent this is, to do a cost analysis before the execution and to set a limit.
# app/config/config.yml
overblog_graphql:
security:
query_max_complexity: 1000
query_max_depth: 10Security
A simple GraphQL attack…
…don't forget to secure every arguments !
public function resolveAll(array $args): Collection
{
$first = $args['first'];
if ($first > 100) {
$first = 100;
}
return $this->postRepo->findAllLimittedBy($first);
}query evilQuery {
posts(first: 9999999999){
id
title
body
author {
name
avatar
}
}
}⚠️ Don't trust user input ⚠️
Monitoring
REST


GraphQL

Documentation
Generated by the schema

-
Quick to proof of concept, just try it !
-
We use it to build all our new features.
-
Integrates well as a proxy in front of legacy code.
-
Frontend devs ❤️ it !
- Needs important work before using it as an official public API, but GitHub is doing it.
- We need more PHP developers using GraphQL !

Year + 1: GraphQL personal feedback
Thanks !
Any questions ?
We work hard to update our democracy (with GraphQL)… 👍