A GraphQL API: from hype to production




5 june 2019
Aurélien David
- CTO at Cap Collectif
- Former JoliCode guy



collective intelligence driven civic start-up that develops participatory applications.

- 23 people 🏃
- 8 devs 👩💻








Consultation
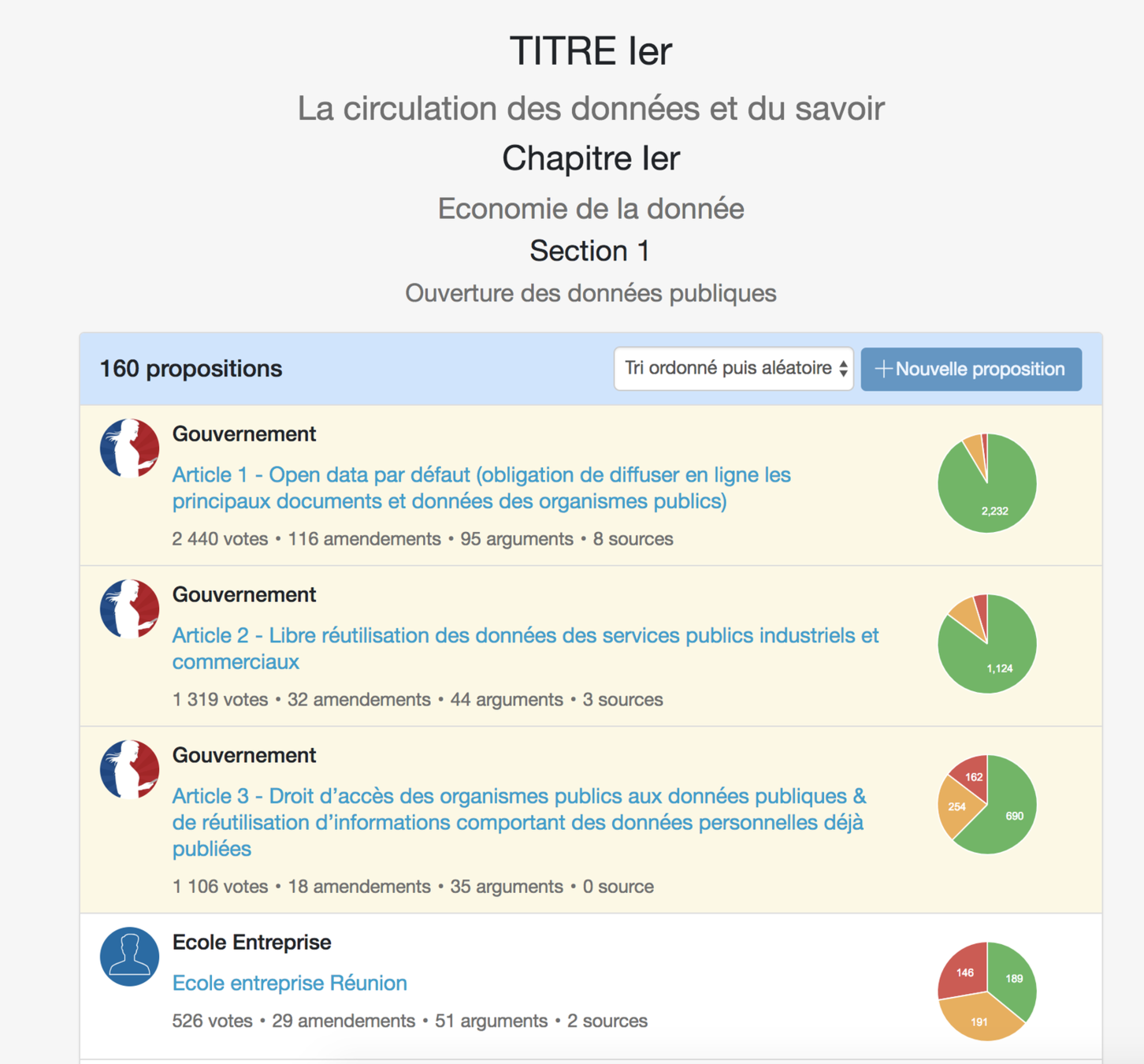
🇫🇷 Le Grand Débat National
+ 1,9 M
Contributions
+ 10 000
Local events
+ 2,7 M
Visitors
Why an API ?

Link between digital and physical participation
Synchronize existing applications
Why an API ?
Transparency and Open Data (in real time)
Data fetching is hard
Over-fetching
Under-fetching
Requests waterfall
GraphQL ?
GraphQL is a syntax that describes how to request data.
Only the transport layer of an API.
Database query language.
A different approach to designing an API
Instead of having several "stupid" endpoints, have a single "smart" endpoint that can take complex queries, and then format the output of data in any form.

Facebook's mobile apps have been powered by GraphQL since 2012. A GraphQL spec was open sourced in 2015 and is now available in many environments and used by teams of all sizes.






Allows the client to ask what he wants.
Easily aggregate data from multiple sources.
Uses a type system to describe the data.
A GraphQL request is called a query and looks like this:
query {
posts {
title
authors {
name
avatar
}
}
}➡️
👏 The way we ask for the data is the way we receive it.
{
"data": {
"posts": [
{
"title": "My first post",
"authors": [
{
"name": "Sacha",
"avatar": "sacha.jpg"
},
{
"name": "Mike",
"avatar": "mike.jpg"
}
]
},
{
"title": "Another great post",
"authors": []
}
]
}
}A query support arguments. For example, if you want to display a specific article, you can specify an id argument to the post field:
query {
post(id: "1"){
id
title
body
comments(first: 2) {
content
}
}
}✌️Adding arguments will allow us to refine our queries, filter, sort, page ...
{
"data": {
"post": {
"id": "1",
"title": "First post",
"body": "Content",
"comments": [
{ "content": "Amazing" },
{ "content": "Great !" }
]
}
}
}➡️
Thinking in graph...
Query (Read)
Mutation (Write)
Subscription (Server-side events)
A GraphQL implementation is organized around a schema.
Here are the root types:
GraphQL Schema Language
# schema.graphql
type User {
name: String!
age: Int
}
type Post {
title: String!
authors: [User]!
}
# Entrypoint
type Query {
posts: [Post]!
post(id: ID!): Post
}1️⃣ We define the types that correspond to our data.
2️⃣ We define the Query type that represent the requestable fields at the root of a query.
🎨 Designing Your Schema
Implementing GraphQL
The reference was developed by Facebook in Node.js.
var { graphql, buildSchema } = require('graphql');
var schema = buildSchema(`
type Query {
hello: String
}
`);
var resolvers = { hello: () => 'Hello world!' };
graphql(schema, '{ hello }', resolvers).then((response) => {
console.log(response);
});



Implementing a resolver 1/2
A resolver is a function that resolves a GraphQL field.
- obj : The previous object (null for a root resolver).
- args : The arguments for the field.
- context : The context shared by all the resolvers to contain information such as the current user, the connection to the DB...
const resolvers = {
Query: {
post(obj, args, context) {
// Use your own business logic here.
return context.db.loadPostByID(args.id);
}
}
}
Implementing a resolver 2/2
const resolvers = {
Post: {
title(obj) {
return obj.name;
}
},
User: {
name(obj) {
return obj.name;
}
avatar(obj, args, context) {
return context.generateAvatarUrl(obj.avatar, args.size);
}
}
}
Now that a Post object is available, GraphQL will continue running to resolve the requested fields.
We explain here, how to resolve a title for a Post and a name and avatar for a User.
query {
post(id: "1") {
title
authors {
name
avatar
}
}
}run Query.post
Query execution — step by step
Execution starts at the top. Resolvers at the same level are executed concurrently.
Execution
run Post.title and Post.authors
run User.name and User.avatar (for each User returned in Post.authors)
Query
Mutation
input PostInput {
title: String
}
type Post {
id: ID!
title: String
}
type Mutation {
createPost(input: PostInput): Post
updatePost(id: ID!, input: PostInput): Post
}GraphQL operations that change data on the server.
1️⃣ We define the inputs that correspond to the data to be sent.
2️⃣ We define possible mutations and their return type.
ℹ️ It is analogous to performing HTTP verbs such as POST, PATCH, and DELETE.
GraphQL clients for Frontend

🔥 Data requirements are declared inside components.
function Post(props) {
const data = useFragment(graphql`
fragment Post_fragment on Post {
title
body
}
`);
return (
<div>
{data.title}
{data.body}
</div>
);
}Relay will make sure every components has the data that they need. 👍
Amazing Frontend Developer Experience
😍 Remove most of data fetching code.
🚆 Optimistic UI and cached data.
✅ Generate Flow/Typescript typings using the strongly-typed schema.
💡 Your frontend developers will be the ones who will push the adoption of GraphQL.
Production

A few things to think about before blindly dumping REST for GraphQL…
Schema Design
Know your domain (really)
Know GraphQL concepts well
GraphQL will not solve your API design problems 😉
Nullability
| Nullable | Non-Nullable |
|---|---|
| DB column can be null ? | If it simply does not make sense for the object/field to exist without a value. |
| Dependence of an external service ? | |
| A chance (even tiny) that it becomes null? | |
| Mostly for a relationship to another object. | Often the case for a scalar. |
Some tips
Train your team

Get inspiration from existing public API.
(and even their mistakes!)
GraphQL Relay Specification
Global Object Identification
Connections
Input Object Mutations
A set of 3 additional conventions to adopt on a GraphQL server.

✅ Implementing it will help you to properly design your schema.
Global Object Identification
# An object with an ID.
interface Node {
# The id of the object.
id: ID!
}
type User implements Node {
id: ID!
name: String
}
type Vote implements Node {
id: ID!
voter: User!
}type Query {
# Fetches an object given its ID.
node(
# The ID of an object.
id: ID!
): Node
}
1️⃣ Add a Node interface.
2️⃣ Add a node field to Query.
Associate a unique id to each object in order to be able to identify and retrieve it again regardless of its type.
✅ All major objects should implement Node. This make easy to fetch any object for a client.
Using global ids
{
node(id: "VXNlcjp1c2VyMQ==") {
__typename
... on User {
username
avatar
}
}
}{
"node": {
"__typename": "User",
"username": "User 1",
"avatar: "toto.jpg"
}
}
➡️
Set up global ids
For example with base64:
{
'type': 'User',
'id': 'user1'
}
VXNlcjp1c2VyMQ==
Connection
- The ability to paginate through the list.
- The ability to ask for information about the connection itself, such as the total number of elements or the presence of elements before or after.
- The ability to request information about relations, such as the cursor or some additional fields.
- The ability to change how our backend does pagination, since the user just uses opaque cursors.
✅ Adopting Connection is a good practice that allows us to integrate our API directly into GraphQL clients, sharing a common format.
A cursor pagination pattern
{
"data": {
"hero": {
"name": "R2-D2",
"friends": {
"totalCount": 3,
"edges": [
{
"node": {
"name": "Han Solo"
},
"cursor": "Y3Vyc29yMg=="
},
{
"node": {
"name": "Leia Organa"
},
"cursor": "Y3Vyc29yMw=="
}
],
"pageInfo": {
"endCursor": "Y3Vyc29yMw==",
"hasNextPage": false
}
}
}
}
}{
hero {
name
friends(first:2 after:"Y3Vyc29yMQ==") {
totalCount
edges {
node {
name
}
cursor
}
pageInfo {
endCursor
hasNextPage
}
}
}
}➡️
Versioning
Since its introduction GraphQL has been described as Version Free.
The shape of the returned data is determined entirely by the client's query. When you're adding new product features, additional fields can be added to the server, leaving existing clients unaffected.
The recommended approach to schema evolution is add-only. This way we preserve current behaviors.
Facebook's GraphQL schema (over 4 years old, 1,000s of types at this point, and under active change by 100s of engineers) has never needed a versioned breaking change, and still supports 4-year old shipped versions of iOS and Android apps (which unfortunately are still being used).
At Facebook they never break the schema... 😱
We'll announce upcoming breaking changes at least three months before making changes to the GraphQL schema, to give integrators time to make the necessary adjustments. Changes go into effect on the first day of a quarter (January 1st, April 1st, July 1st, or October 1st). For example, if we announce a change on January 15th, it will be made on July 1st.
At GitHub they deprecate and then suppress after 3 to 6 months. 🏄
type Consultation {
votesCount @deprecated(reason: 'Field will be removed.')
}Deprecating with GraphQL
Using a directive
Don't underestimate the time necessary to design a good contract. Especially since the names you choose will stay forever.
A Version Free API is hard…
💡 Using Replay Spec strictly should avoid most BCs but it's still your job to anticipate the evolutions.
🙈 We keep some parts of our schema in preview, to stabilize our structure and naming.
🤔 Remember nothing prevents a GraphQL API from being versioned.
GraphQL and caching
A GraphQL query can be written in different ways and asked for the same data.
The same URL is called for different queries, producing different results, making the network cache more difficult to apply.
network cache
GraphQL and caching
network cache
✅ It's possible !
Varnish cache POST requests on our GraphQL endpoint by hashing the request body (see how).
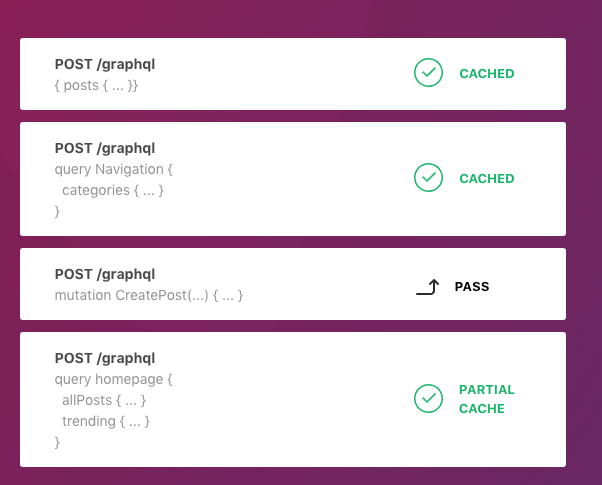
A CDN built specifically for GraphQL applications.

N+1 problem
The nightmare of your DevOps 😀
query {
authors { # fetches authors (1 query)
name
address { # fetches address for each author (N queries for N authors)
country
}
}
} # Therefore = N+1 round trips✅ Useful for optimizing nested queries and reduce the number of queries to data storage.
Batching : within a single query, allow you to run a batch operation instead of many small searches.
DataLoader, a data loading mechanism.
A batch loading function accepts an Array of keys, and returns a Promise which resolves to an Array of values.
# Instead of 3 individual SQL requests :
SELECT * FROM votes WHERE id IN ( '1', '2', '3' )Memoization Caching : within the same query, keep in memory the result of a job to avoid duplicating it.
DataLoader, a data loading mechanism.
Application Caching : we can also use a DataLoader key, to cache it's result between requests.
ℹ️ Use DataLoader from the beginning. It's a best-practice.
Security
Authentication and Authorization❓
💡 Field depending on authorization should be nullable (eg: email).

Authentication is independent.
Authorization is done at the field level of a GraphQL schema.
Implementations provide some helpers for access control and public visibility.
Security
⚠️ Denial of service attacks ⚠️
Sending a heavy query can consume too many resources, for example: user ➡️ friends ➡️ friends ➡️ friends …
One way to prevent this is, to do a cost analysis before the execution and to set a limit.
🛡️ We limit from 1 to 100 the size of pagination.
Security
⚠️ Rate Limiting ⚠️
REST
GraphQL
We can use endpoints and limit the number of requests per hour.
A single complex GraphQL call could be the equivalent of thousands of REST requests. 😨
⚙️ You need a dedicated service to calculate the cost of a query.
ℹ️ The GitHub GraphQL API limit to 5,000 nodes per hour.
Monitoring
REST


GraphQL

Monitoring
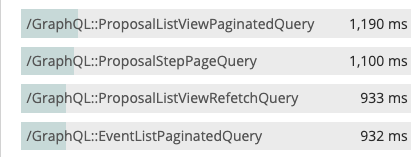
For an internal API, it's simple, just give a name to your queries. Then use it as the name of the transaction.
💡 There is an ESLint rule for that.
query ProposalListViewPaginatedQuery {
# your query
}Monitoring
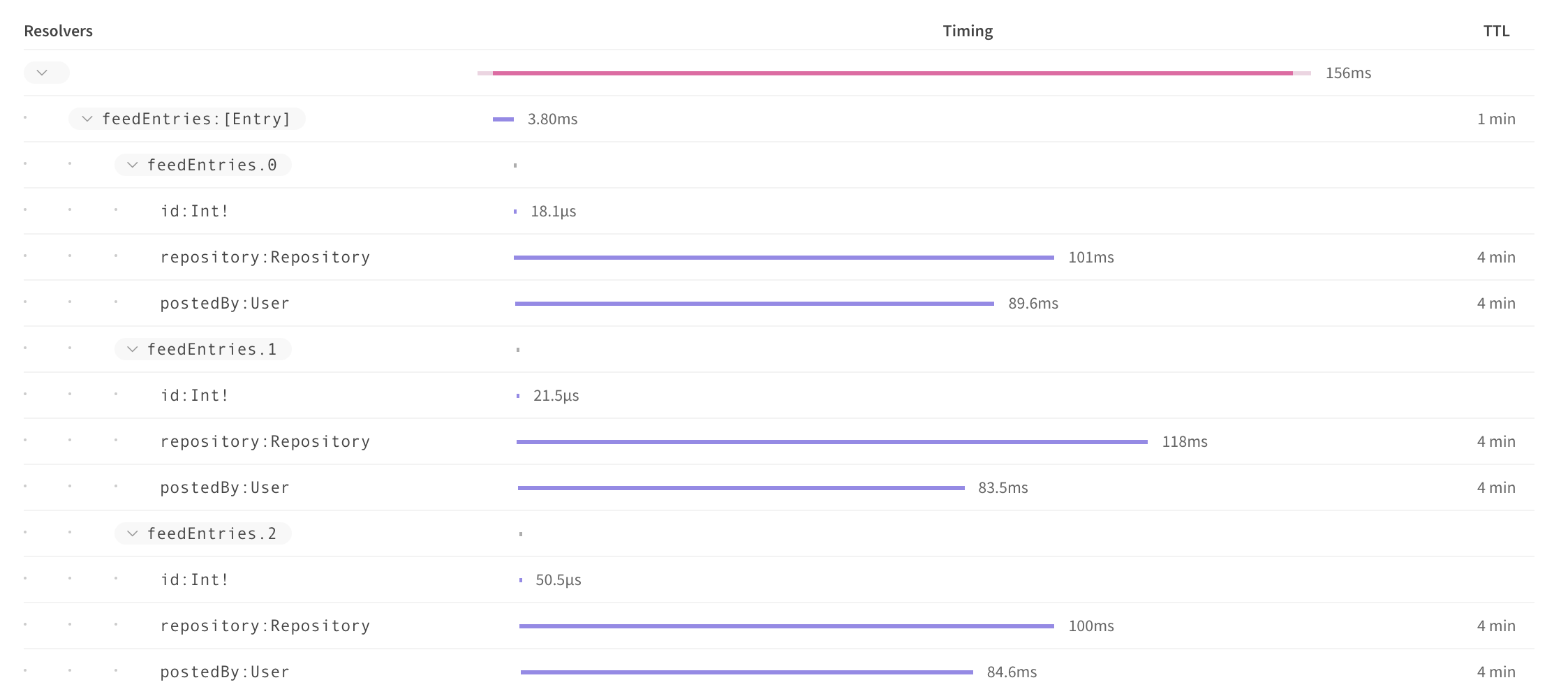
For a public API, you will need a specific tool such as Apollo Engine.
⚠️ Available in NodeJS only for now.
Documentation
A promise of GraphQL is to generate documentation from the schema.

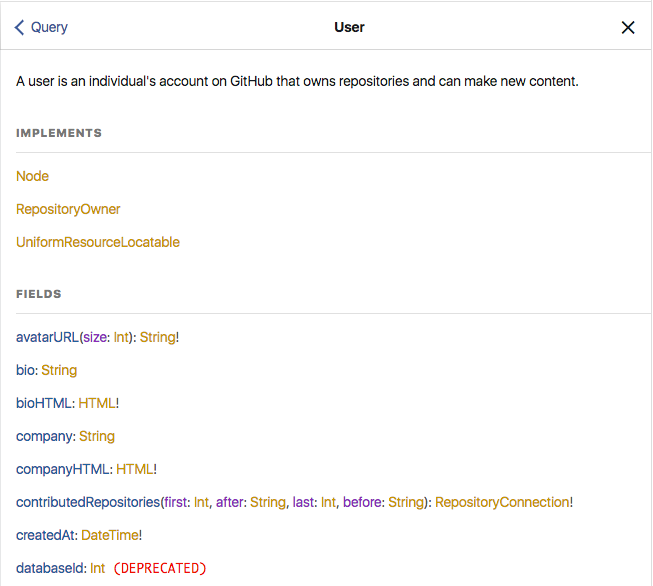
Documentation
In practice…
Write educational materials for user onboarding.
Provide many exemples and guides on how to use it.
Complete the GraphQL schema with descriptions for every type, fields, interface… (Checkout graphql-schema-linter)
We even developed our own API documentation generation tool. 😀
Explain your API entrypoints.
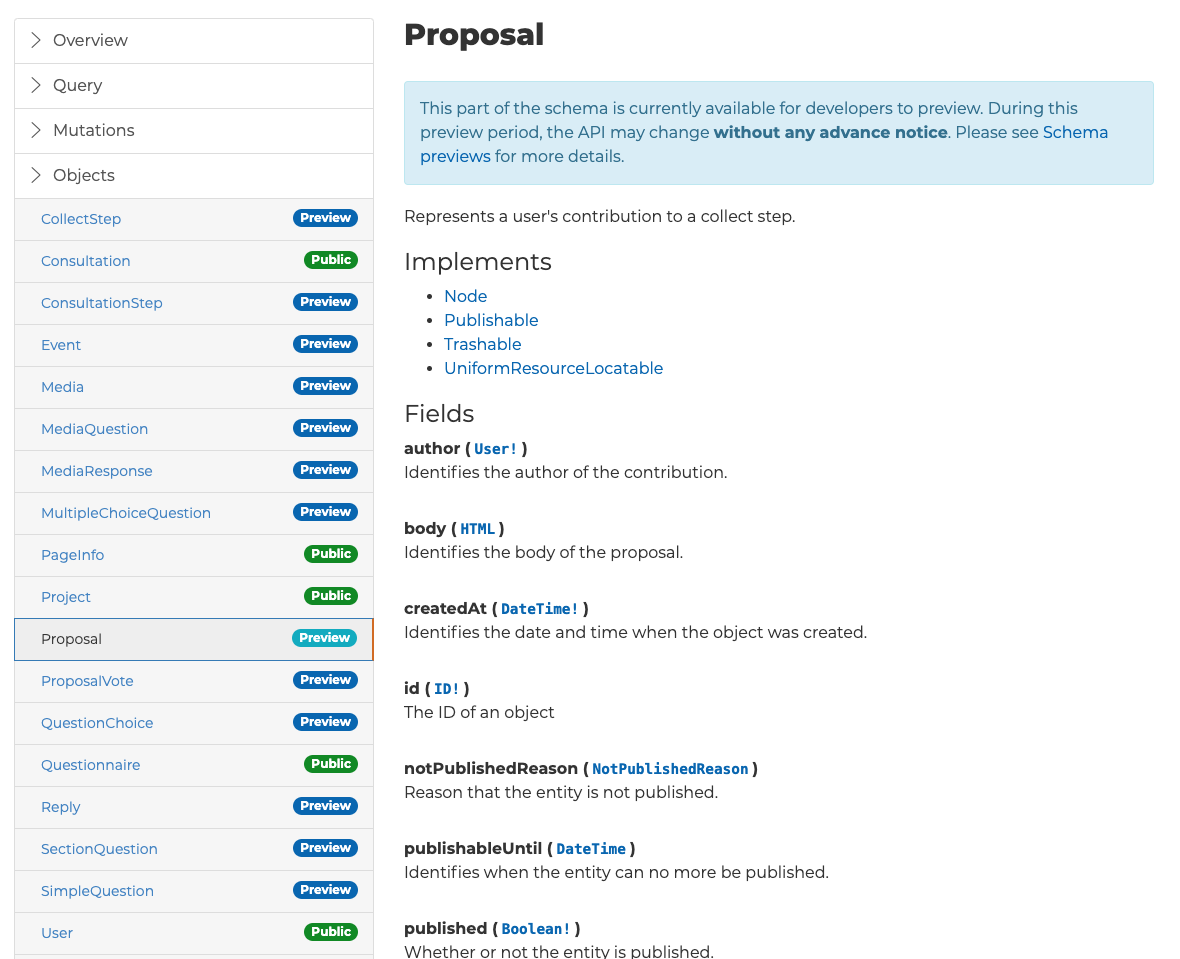
When you are all done,
having an always up to date API documentation is great ! 🎉

Integrating GraphiQL IDE can help you users explore live data ! It can be used as a documentation tool.
Documentation
Checkout granddebat.fr/developer
-
Quick to proof of concept, just try it !
-
We use it to build everything.
-
Integrates well as a proxy in front of legacy code.
-
Frontend devs ❤️ it's simplicity !
-
Backend devs ❤️ managing a schema and not endpoints !
-
Backend devs have some new challenges to solve 😉
- Needs important work before using it as an official public API, but we are confident doing it.

Year + 2: GraphQL personal feedback
Thanks !
Any questions ?
We work hard to update our democracy (with GraphQL)… 👍
Slides: spyl.net/slides/web2day-2019
Bonus #1 Monitoring
What if GraphQL enable us more monitoring ?
What fields are our clients using ?

Query
Analytics
query {
consultations {
title
votesCount
}
}No magic but some analysis... 😉
Type: Query
Field: consultations
Client: 1234
Type: Consultation
Field: title
Client: 1234
Type: Consultation
Field: votesCount
Client: 1234Knowing the statistics of use of our schema
This is the key to trusting in the continious evolution of your API!
GraphQL allows it because it is the client who describes the needs.

Bonus #2 Avoid accidental breaking changes...

Save the schema with the code.
✅ On s'assure que le schéma est bien à jour à chaque commit.

graphql:dump-schema
--schema public
--file schema.public.graphql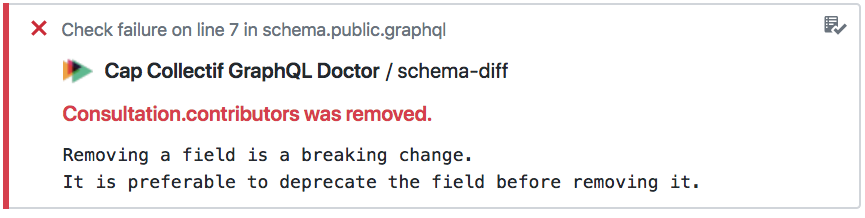
Spot breaking changes on the schema
Expliquer le problème
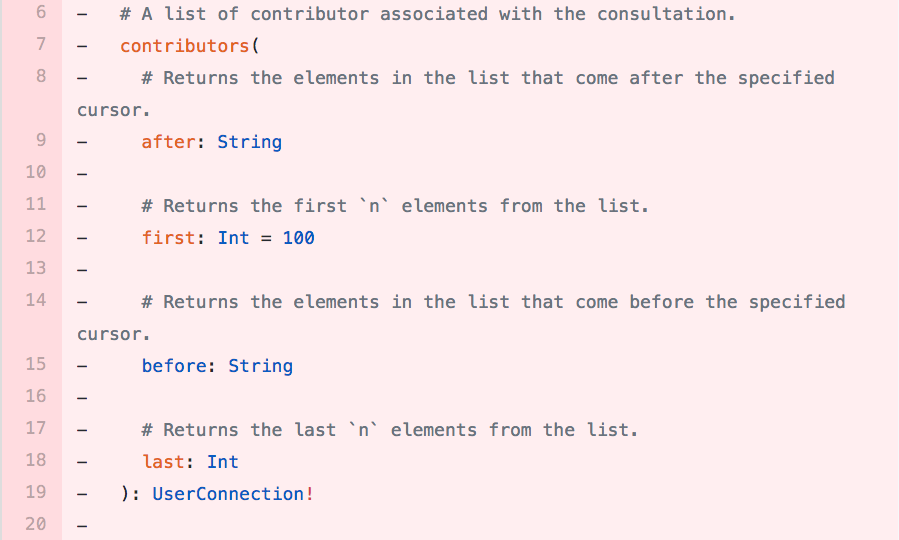
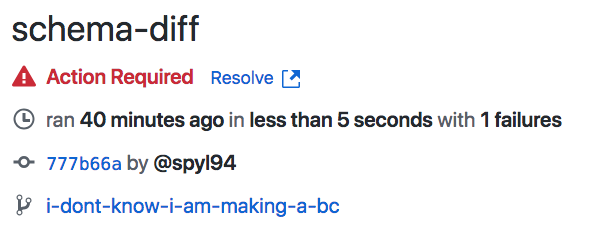
Continuous integration fails in case of BC!
✌️ No risk to merge a Breaking Change !
github.com/cap-collectif/graphql-doctor
Checkout our Demo !
Designing great mutations... 🚀
-
Naming. Start with a verb (create, update, delete, like, reload…) then the subject.
-
Specificity. Create a mutation for every semantic user actions.
-
Input object. Use a unique input type, required, as the only argument.
-
Payload. Use a unique payload type for every mutation and add the return data as fields of this type.